4. PyMySQL 익혀보기 > 4-6. cmd로 데이터 적재하기
cmd로 데이터 적재하기
여러분의 데이터베이스에 정말 엄청 큰 용량의 데이터가 계속해서 저장되고 있고, 이를 실시간으로 분석해야하는 상황을 가정해 봅시다. 컬럼의 개수는 100개가 넘어가고, row 수는 백만, 천만 단위입니다. 엑셀로는 100만건부터 표현이 불가능합니다. Pandas로 컬럼부터 삭제하고, 조건을 걸어서 선택하고, 혹시 모르니 따로 저장해두면서 변수마다 메모리를 엄청 잡아먹을 겁니다. 읽어오는 속도도 느리고, 무얼 어떻게 해야할지도 모르는 답답한 상황이죠. 그럴때! 우리는 cmd를 통해 database에 올려 두고 sql로 쉽게 원하는 데이터를 가져올 수 있습니다.
앞서 소개시켜드린 for문을 이용한 작업은 row가 1000건이 넘어가는 순간 급격히 느려지기 시작합니다. 이것이 for문의 한계입니다. numpy나 scrapy를 통해 느끼셨겠지만 for문을 통한 작업은 각각을 메모리에 올리고, 처리해야 하므로 느립니다. 한번에 하나씩 문자는 문자대로, 숫자는 숫자대로 따로따로 인식해 처리하죠. 몇만, 몇백만건을 처리해야하는 작업에는 너무 느려서 어울리지 않습니다. scrapy처럼 일단 필요한 부분을 다 가져와버리는 편이 효과적이죠. numpy처럼 자료를 array(쉽게 말해 행렬이나 텐서)로 처리하는 방법도 있습니다.
그래서 우리는
- 엄청 큰 csv나 txt파일을 바로 db에 올리고,
- PyMySQL로 원하는 조건을 쿼리로 선택해
- pandas로 바로 dataframe을 만들어 작업하는 환경을 만들어 볼겁니다.
나중에는 csv나 txt가 아니라 자동으로 실시간 데이터를 db에 적재하고, 이를 바로 PyMySQL로 가져와서 작업하실 수 있을겁니다.
데이터를 적재하는 단계는 크게 두 개이며, 이후 PyMySQL과 pandas를 이용해 원하는 데이터를 dataframe으로 가져올 수 있습니다.
- MySQL 환경변수 설정
- cmd 환경에서 데이터를 DB에 적재하기
실습에서 사용할 데이터는 이곳에서 다운받을 수 있습니다.
1. MySQL 환경변수 설정
환경변수 설정은 윈도우10을 기준으로 합니다. 다른 환경을 사용하실 경우 구글링을 해주세요. 우선 윈도우 기본 cmd (명령프롬프트)에서 MySQL을 제어하기 위해서는 환경변수를 설정해주어야 합니다. 이 블로그 글을 보고 따라하니 정상적으로 작동되었고, 아래 스텝은 요약한 내용입니다.
- 제어판>모든 제어판 항목 >시스템 (혹은 Window + Pause 키) > 고급시스템 설정 (화면 우측에 있을것) mysqld.exe 파일이 있는 폴더로 들어갑니다.
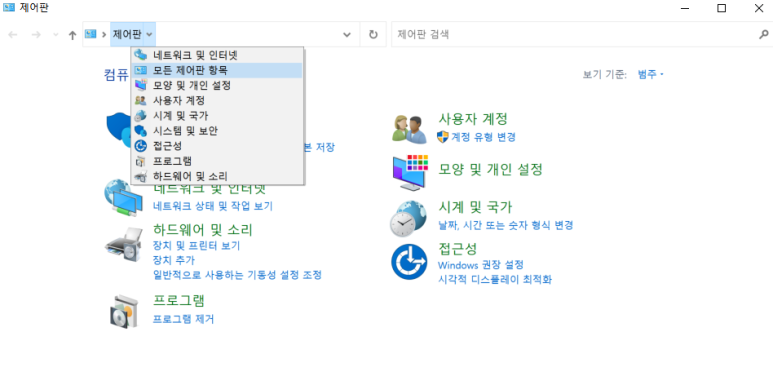
- 환경변수 클릭 > 새로 뜨는 창에서 '시스템 변수' 중 Path 경로를 찾아 더블클릭!
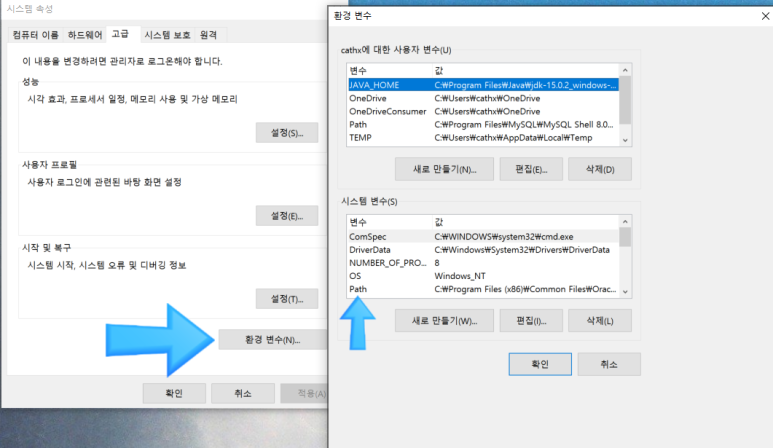
- '새로만들기'를 누르고 mysqld.exe 파일이 들어있는 폴더 경로를 추가! 우선 MySQL 설치했던 파일을 찾아서 'mysqld.exe'파일이 들어 있는 폴더를 찾아야 합니다. 그리고 경로 텍스트를 복사해서 '새로만들기'에 붙여넣고 확인! (작성자의 경우 C:\Program Files\MySQL\MySQL Shell 8.0\bin\ 여기에 들어있었습니다.)
- cmd에서 mysql --version 이라고 쳐서 아래와 같은 결과가 나오면 성공!

2. cmd 환경에서 데이터를 DB에 적재하기
총 6개의 스텝입니다. 하나씩 차근차근 따라서 꼭 성공해보세요!
1. cmd 창을 엽니다.
2. cmd에서 mysql 접속
mysql -u root -p --local-infile 이렇게 입력하고 엔터를 누른 후, mysql root 계정의 비밀번호를 입력합니다. 만약 안된다면 뒤의 --local-infile을 제거하고 접속해 줍니다.
3. local_infile=true
> mysql show global variables like 'local_infile'; 앞부분의 > mysql은 이제 기본을 나올겁니다. 박스 안에 local_infile이 off로 처리되어 있다면 mysql> set global local_infile=true;를 입력하세요. 그리고 mysql 문법처럼 쿼리가 끝날 때 ; 를 꼭 써주셔야 한답니다! 이후 쿨하게 exit을 눌러서 나가줍니다.
4. 확인하기
cmd창을 다시 키고 mysql --local_infile -u root -p으로 접속한 뒤, > mysql show global variables like 'local_infile';를 다시 확인해 줍니다. on이 나오면 드디어 csv, txt 등 파일을 db에 넣어줄 거예요.
5. DB, TABLE 만들기 (DB는 이미 만들었다면 pass!)
DB를 선택하고(use 원하는 DataBase), TABLE을 만들어 줍니다. 문법은 똑같으니 cmd창에서 진행해도 좋고, PyMySQL로 진행하셔도 됩니다.
6. data import
TABLE에 데이터를 적재할겁니다.
# cmd에서 입력하는 코드
> LOAD DATA LOCAL INFILE "절대경로/BUS_STATION_BOARDING_MONTH_202109.txt"
> INTO TABLE dbName.tableName
> FIELDS TERMINATED BY "|"
> LINES TERMINATED BY "\n"
> IGNORE 1 ROWS
> -- (`column1`, `column2`, ...)
이런 식으로 데이터를 넣어 줍니다. 백만건 기준으로 약 5~6초 정도 소요됩니다. 위의 for문으로는 3시간으로도 다 하지 못했습니다.
처음 할 땐 분명 중간에 에러가 뜰텐데, 이때 의심해봐야 할 건
- 넣고자 하는 데이터의 컬럼과 CREATE TABLE 에서 설정한 컬럼이 정확하게 일치하는가? (pandas에서 조작한 뒤 저장한 csv, xlsx 파일은 Unnamed: 0과 같은 컬럼이 하나 더 생기기도 하므로 꼭 확인해 볼 필요있습니다.)
- 한글이 포함된 파일이라면 utf-8로 인코딩이 잘 되었는가?
- 환경변수 설정이 잘 되었는가? (show globals 에서 Value가 ON인지 수시로 확인하기)
- 오타가 없는가?
앞으로는 pymysql로 jupyter notebook이든, vscode든, pycharm이든 PyMySQL로 원하는 데이터를 가져올 수 있겠죠!
2022년 9월 24일