4. 데이터 시각화 > 4-3. ggplot2 라이브러리로 시각화하기
ggplot2 라이브러리로 시각화하기
🧭 목차
- ggplot2 라이브러리
- ggplot2 라이브러리로 시각화하기
이번 장에서는 시각화에 특화된 'ggplot2 라이브러리'에 대해 학습해 보겠습니다.
1) ggplot2 라이브러리
ggplot2 라이브러리를 사용하면 보다 직관적이고 효율적인 시각화 작업이 가능해집니다. 코드 작성이 간편해지고, 그래프 속성의 추가와 삭제가 자유롭기 때문입니다.
ggplot2의 기본 표현식을 살펴보면 다음과 같습니다.
-
ggplot(data=데이터명, aes(x = x축 변수, y = y축 변수, col = 색상 변수)) + geom_그래프명()-
data: 시각화하려는 데이터
-
aesthetics: 시각화의 미학적, 시각적 설정 (예) x축, y축, 속성의 색상/모양/사이즈 등
-
geometrics: 시각화의 기하학적 형태 (예) 산점도, 막대그래프, 선그래프 등
# 예시: gapminder 데이터를 사용해, 대륙별 1인당 GDP(gdpPercap)에 따른 기대 수명(lifeExp)을 시각화 library(ggplot2) ggplot(data=gapminder, aes(x = gdpPercap, y = lifeExp, col = continent, size = pop)) + # 마커 크기를 인구 수에 비례 geom_point(alpha = 0.5) + # 마커 투명도 설정 scale_x_log10()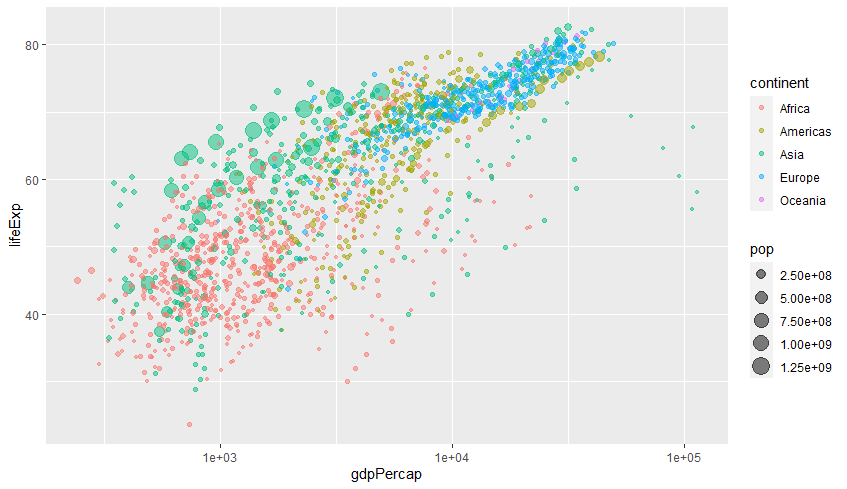
-
여기서 한 가지 주목할 점은 '시각화의 미학적, 시각적 설정'이 (1) aes() 안에서 설정할 때와 (2) geom_() 안에서 설정할 때 다르게 작동한다는 것입니다.
-
aes()안에서 설정하는 경우ggplot(data=gapminder, aes(x = gdpPercap, y = lifeExp, col = 'blue')) + geom_point() + geom_line() + scale_x_log10() # 그래프 중첩 가능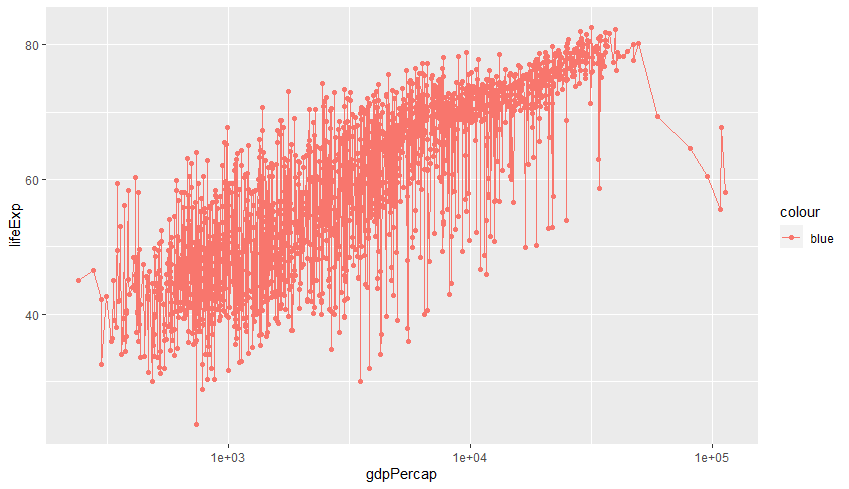
색상이 제대로 적용되지 않고, 'blue'라는 문자열로 인식된 것을 확인할 수 있습니다.
aes()안에서는col에 속성변수를 지정해야 색상이 제대로 인식됩니다.# 1. 연속형 속성변수 [왼쪽 사진] ggplot(data=gapminder, aes(x = gdpPercap, y = lifeExp, col=year)) + geom_point() + geom_line() + scale_x_log10() # 2. 범주형 속성변수 [오른쪽 사진] # factor(): 연속형 속성변수를 범주형 속성변수로 변환 ggplot(data=gapminder, aes(x = gdpPercap, y = lifeExp, col=factor(year))) + geom_point() + geom_line() + scale_x_log10()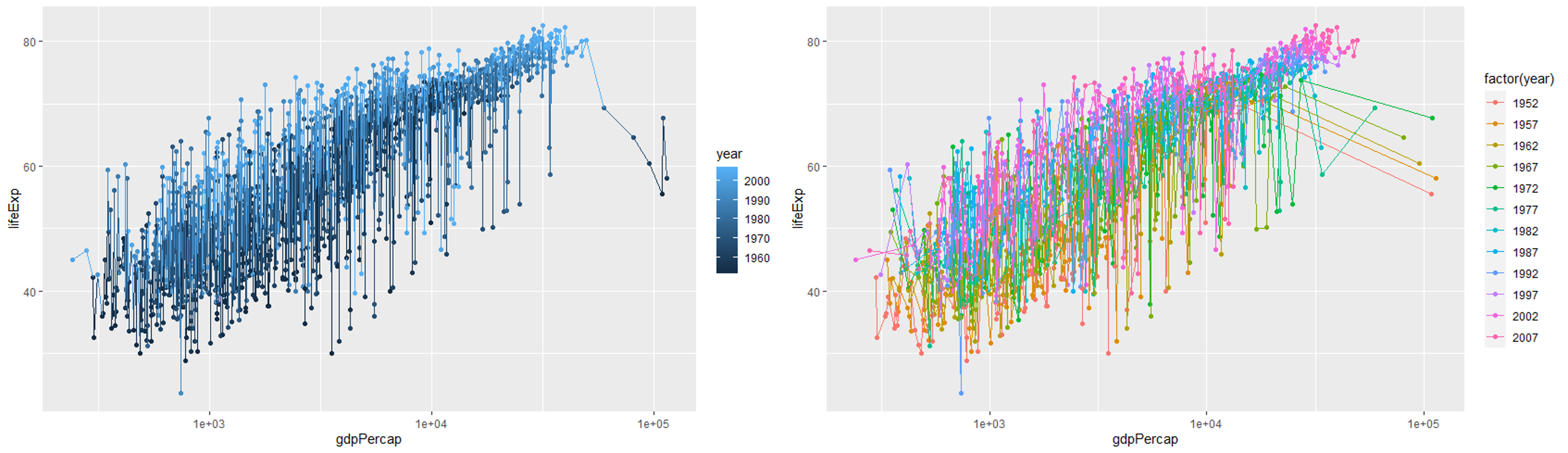
-
geom()안에서 설정하는 경우ggplot(data=gapminder, aes(x = gdpPercap, y = lifeExp)) + geom_point(col = 'blue') + geom_line(col = 'yellow') + scale_x_log10()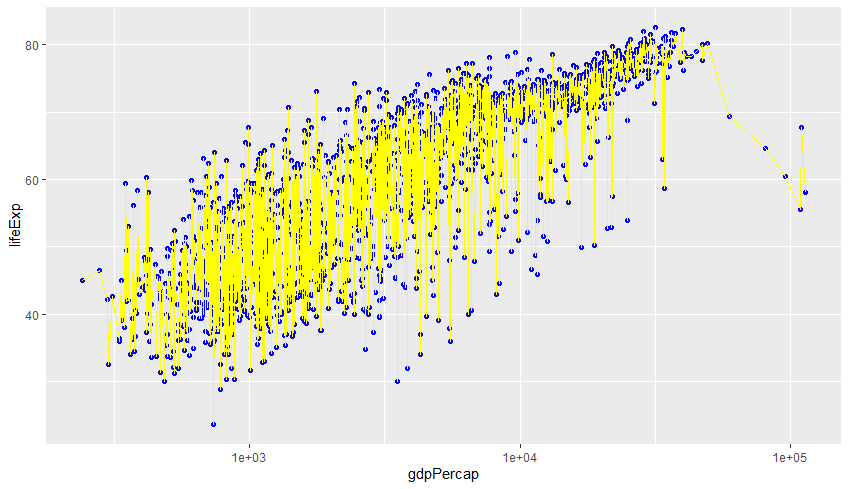
색상이 제대로 인식되어 적용된 것을 확인할 수 있습니다.
또한
aes()내의 설정은 그래프 전체에 영향을 미치지만,geom()내의 설정은 해당 그래프에만 영향을 줍니다.
2) ggplot2 라이브러리로 시각화하기
시각화의 목적은 데이터에 내재된 의미, 즉 변화 · 구성 · 분포 등을 명확히 드러내는 것입니다. 대표적인 시각화 방법을 몇 가지 살펴보겠습니다.
💡 geom_그래프명() 함수의 주요 argument
일단은 이런 게 있구나 하고 읽고 넘어갑니다.
stat(statistical transformation): 해당 그래프에 데이터를 어떻게 반영할지 결정한다.
종류 설명 해당 값이 기본인 함수 count y축이 'x축 변수 값의 빈도수'가 된다. geom_bar() bin y축이 'x축 변수 값의 구간 빈도수'가 된다. geom_histogram() identity x, y축에 입력된 데이터를 그대로 사용한다. geom_point(), geom_line()
position: 해당 그래프에 도형을 어떻게 배치할지 결정한다.
종류 설명 해당 값이 기본인 함수 stack 누적 쌓기(차곡차곡) geom_bar() identity 겹쳐서 그리기 geom_point(), geom_line() dodge 옆에 그리기
(1) 비교/순위: 막대그래프
데이터 간의 크기를 비교하거나 순위를 매기는 데는 주로 막대그래프가 유용합니다.
-
geom_bar(): y축에 x축 변수 값의 빈도(count)를 나타낸다.mpg %>% ggplot(aes(class)) + geom_bar()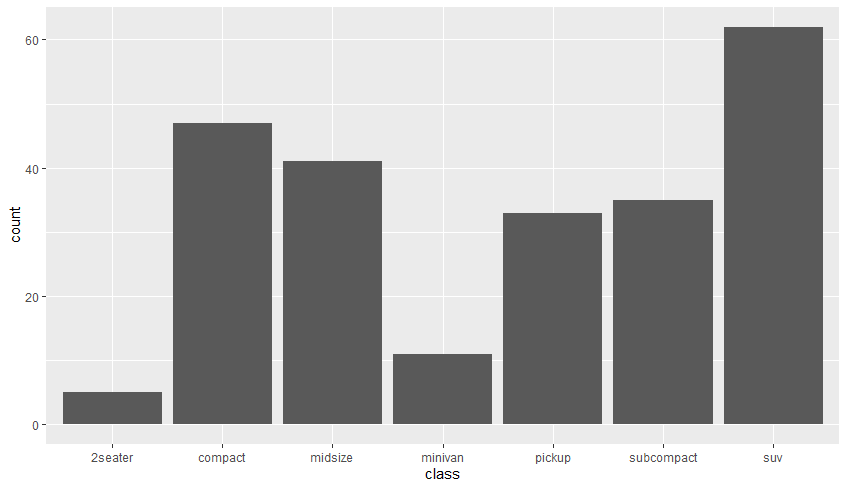
-
geom_col(): y축에 x축 변수의 평균값을 나타낸다.mpg %>% group_by(manufacturer) %>% summarise(avg = mean(cty)) %>% ggplot(aes(manufacturer, avg)) + geom_col() # geom_col() = geom_bar(stat = 'identity') mpg %>% group_by(manufacturer) %>% summarise(avg = mean(cty)) %>% ggplot(aes(manufacturer, avg)) + geom_bar(stat = 'identity')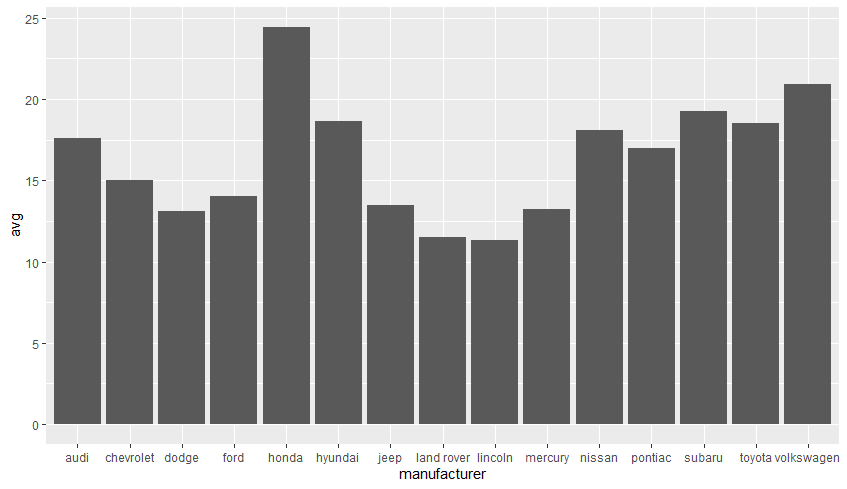
막대그래프의 y축 구성요소를 세부적으로 분리하여 보고 싶은 경우, (1) fill과 (2) position 옵션을 사용하면 됩니다.
-
기본 막대그래프
diamonds %>% ggplot(aes(color)) + geom_bar()
-
fill옵션 사용diamonds %>% ggplot(aes(color, fill = cut)) + geom_bar()
-
position = 'dodge'diamonds %>% ggplot(aes(color, fill = cut)) + geom_bar(position = 'dodge')
-
position = 'identity'# 겹쳐서 그리기 # 값이 가장 큰 것이 보이게 됨 diamonds %>% ggplot(aes(color, fill = cut)) + geom_bar(position = 'identity')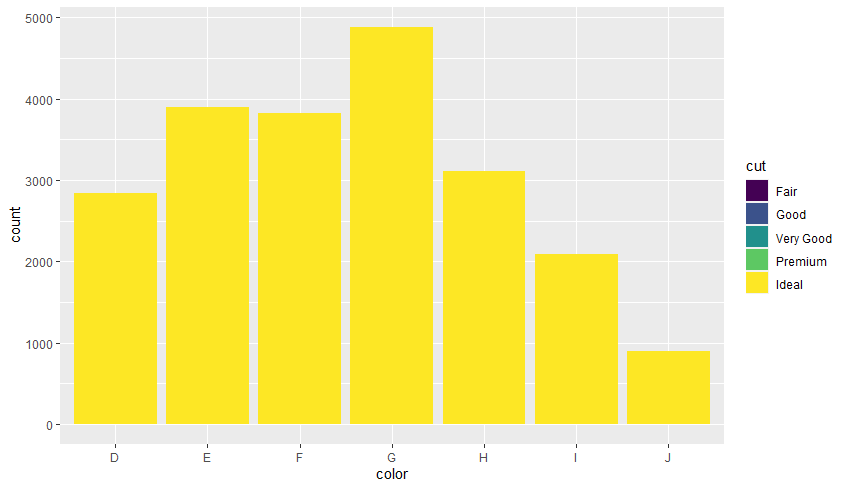
마지막으로 그래프의 축과 관련된 함수들을 알아보겠습니다.
-
reorder(축 속성, 정렬 기준): 축의 속성값의 정렬순서를 바꿀 때 사용한다.# 오름차순 [왼쪽 사진] gapminder %>% filter(year == 2002 & continent == 'Asia') %>% ggplot(aes(reorder(country, pop), pop)) + # x축(country)를 인구수(pop)를 기준으로 정렬 geom_bar(stat = 'identity') # 내림차순: - 정렬기준 [오른쪽 사진] gapminder %>% filter(year == 2002 & continent == 'Asia') %>% ggplot(aes(reorder(country, -pop), pop)) + geom_bar(stat = 'identity')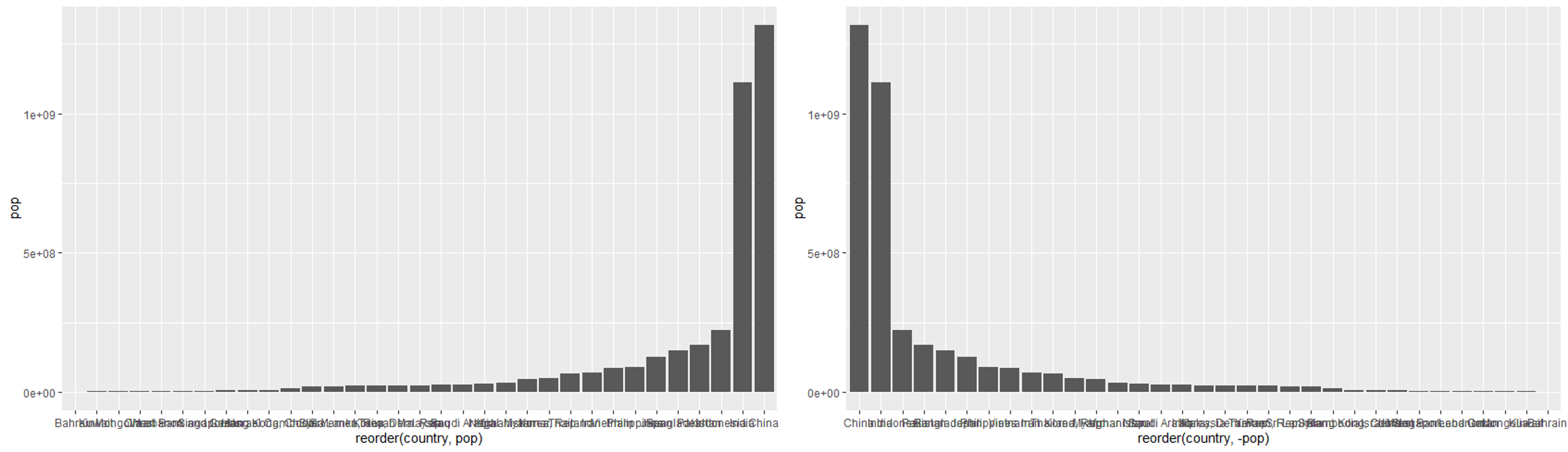
-
coord_flip(): x축과 y축의 위치를 바꿀 때(뒤집을 때) 사용한다.- 위치는 y=x 선을 기준으로 바뀐다.
- 바뀐 모습을 보여줄 뿐, x축과 y축 속성은 변하지 않는다.
gapminder %>% filter(year == 2002 & continent == 'Asia') %>% ggplot(aes(reorder(country, pop), pop)) + geom_bar(stat = 'identity') + coord_flip() # 모습만 바뀌었을 뿐, # 여전히 x축은 country, y축은 pop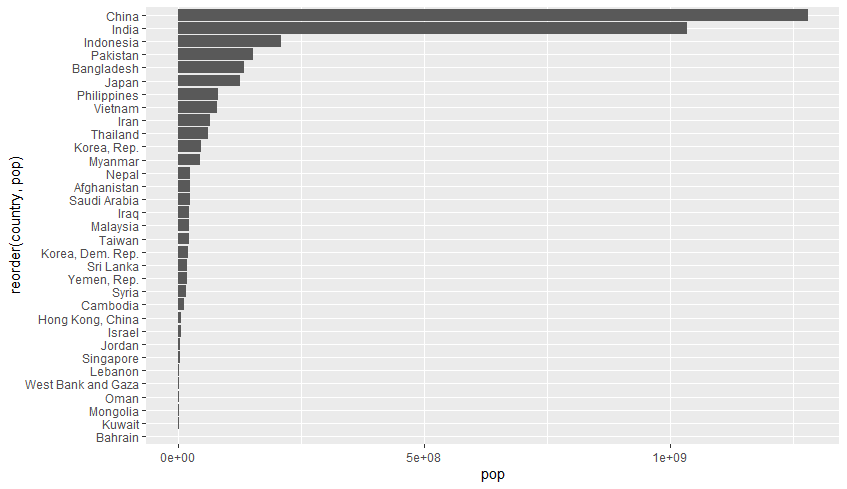
(2) 변화 추세: 점/선 그래프
특정 시점부터 일정 기간 동안의 데이터 값의 변화를 보여줄 때는, 점과 선 그래프를 모두 사용하는 것이 좋습니다.
gapminder %>%
filter(country == 'Korea, Rep.') %>%
ggplot(aes(year, lifeExp, col=country)) +
geom_point() + geom_line()
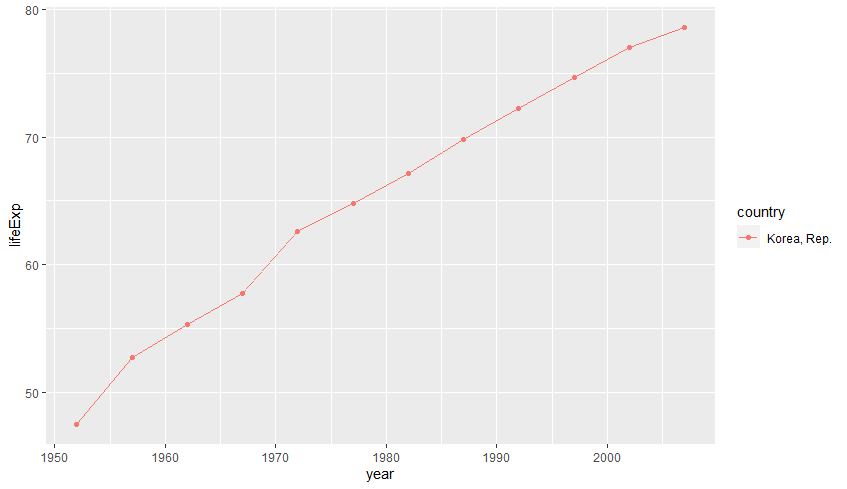
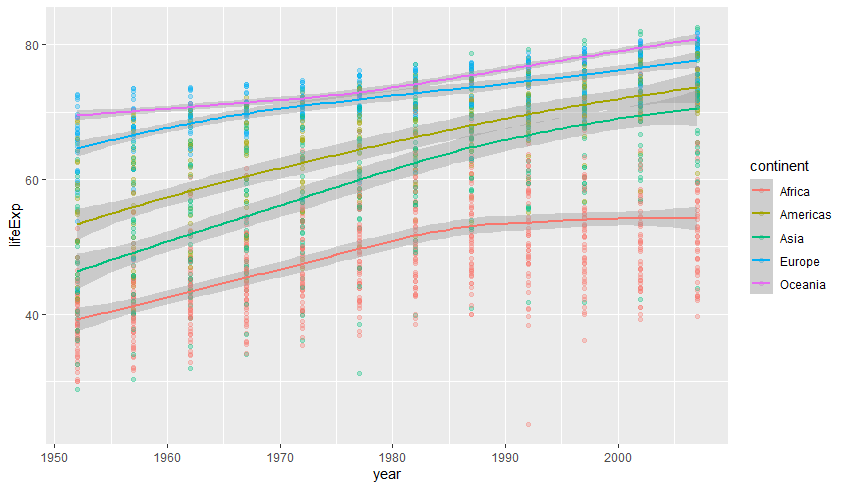
추가로 geom_smooth() 함수를 이용하면 데이터의 평균적인 추세선을 표시할 수 있습니다.
gapminder %>%
ggplot(aes(year, lifeExp, col=continent)) +
geom_point(alpha=0.3) + geom_smooth()
(3) 분포 혹은 구성 비율: 히스토그램 /박스플롯
분포를 보고자 하는 데이터의 속성이 연속형 변수인 경우 히스토그램을 사용합니다.
💡 연속형 변수 v.s. 범주형 변수
- 연속형 변수(continuous)
- 크기와 양을 나타내는 변수로 구간이 연속된다.
- 분포 시각화: 히스토그램(histogram) 사용
- 범주형 변수(categorical + discrete)
- 대상을 분류하는 의미를 갖는 변수로 구간이 끊어진다.
- 분포 시각화: 막대그래프(barplot) 사용
-
geom_histogram()gapminder %>% filter(year == 1997) %>% ggplot(aes(lifeExp)) + geom_histogram()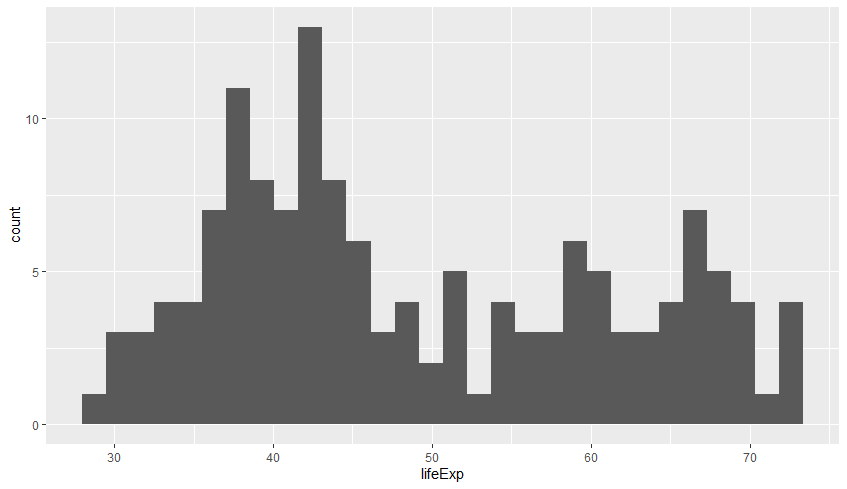
위의 예시처럼 특정 속성이 아닌, 여러 항목의 분포를 동시에 비교하고 싶다면 박스플롯을 사용하면 됩니다.
-
geom_boxplot()gapminder %>% filter(year == 1997) %>% ggplot(aes(continent, lifeExp)) + geom_boxplot()
위 그래프에서 점은 이상값(정상 분포에서 벗어난 데이터)으로, 데이터 정제 과정에서 제거하는 것이 좋습니다. 이처럼 박스플롯은 이상값 확인에도 사용됩니다.
2022년 9월 24일