4. 군집화(Clustering) > 4-1. 군집화란?
군집화란?
이번 파트에서는 비지도학습, 즉 정답값이 존재하지 않는 학습 방법의 하나인 '군집화(Clustering)'에 대해서 학습해보겠습니다.
군집화 기본 개념
군집화는 개체들을 비슷한 것끼리 그룹을 나누는 것을 말합니다.이때 비슷하다는 것은 유사도(=거리)를 의미하는데 유사도는 높을수록, 거리값은 적을수록 비슷한 특성을 가집니다. 그룹을 나눈다는 점에서 분류(classification)과 비슷하게 보이지만, 분류는 이미 정답값이 있어서 어떤 그룹으로 묶을지 생각하고 나누는 지도학습에 속한다는 점에서 확연한 차이가 있습니다. 군집화를 통해서 주어진 데이터에서 구조를 파악할 수 있으며, 데이터 특성을 알 수 있습니다.
✔️ 용어정리 해당 교안에서 같은 의미로 사용되는 용어입니다.
- 군집 = 클러스터 = 그룹
- 개체 = 관찰값 = 데이터포인트
군집화의 방법과 알고리즘은 다양하지만, 근본적인 원리는 하나입니다. 같은 군집끼리의 응집도(cohension)는 최대화하고 다른 군집과의 분리도(separation)도 최대화하는 것입니다. 즉 가까운 것은 더 가까이, 먼 것은 더 멀리 위치하도록 만들어주는 것이 군집화의 정확도를 높여주는 과정이라고 생각하면 됩니다.
참고자료: 응집도, 분리도 - 군집분석의 개념 및 유형
군집화 활용 분야
군집화는 다양한 분야에서 사용되고 있으며, 할 수 있습니다. 특히 퇴근 자연어나 이미지와 군집화를 접목하여 AI의 기술 발전에 큰 역할을 하기도 합니다.
군집화를 활용할 수 있는 분야 몇 가지를 소개 하자면, 우선 마케팅 분야가 있습니다. 수많은 고객 데이터를 통해 비슷한 유형의 고객들을 분류하여 (이때의 분류는 클러스터링을 의미함) 효율적으로 관리할 수 있습니다. 최근 떠오르는 '개인화 서비스' 또한 군집화를 활용하여 비슷한 유형의 사용자에게는 비슷한 서비스를 제공합니다. 또한 제조업 분야에서는 이상치 탐지에 군집화를 활용합니다. 공장에서 생산한 생산품이 표준적인 범위에서 넘어선 이상치(outlier)값을 가지면 불량품으로 구별하는데, 이때 이상치에 대한 정답값(라벨)이 없을 때 분류(classification)이 아닌 군집화 기법을 사용할 수 있습니다. 이 외에도 의료 분야에서는 특정 질병에 대한 공간 군집 분석을 통해 질병의 분포 면적과 확산 경로 등을 파악하는 역학 조사 등에서 활용하기도 합니다.
참고 자료: 머신러닝-비지도학습(TCPschool)
군집화의 종류
군집화는 크게 두 가지 종류로 구분할 수 있습니다.
첫 번째는 계층적 군집입니다. 계층적 군집은 단어 그대로 각 군집이 계층을 통해 구분되는 방법으로, 군집의 개수를 정확하게 결정하는 목적이 아닌 데이터의 구조 및 어떤 군집이 이루어졌는지 확인하는 목적이 강합니다.
- 장점
- 클러스터 개수를 미리 설정하지 않아도 됨.
- 텍스트, 수치 상관없이 모든 클러스터링 기법에서 사용할 수 있음.
- 단점
- 모든 쌍에 대해서 반복적으로 유사도를 구해야 하므로 계산량이 매우 많음.
두 번째는 분할적 군집입니다. 분할적 군집은 각 개체가 하나의 군집에만 속하도록 구분하는 방법으로, 서로 관계성이 드러나지 않는 다수의 군집을 생성합니다.
- 장점
- 계층적 군집에 비해 계산량이 적음. (군집간의 계층관계를 파악할 필요없는 상황에 적합)
- 단점
- 일반적으로 미리 몇 개의 군집으로 나뉠 지 정해야 함. (중심점의 개수, 반지름의 크기 등)
계층적 군집과 분할적 군집은 각각 하위에 세부 군집 방법이 존재합니다. 다음 장 부터 세부 내용을 하나씩 살펴볼 예정이며, 전체적 구조는 다음과 같습니다.
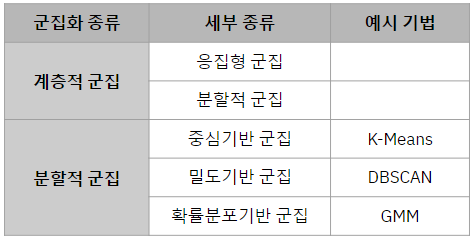
지금부터 군집화의 종류를 하나 씩 자세하게 알아보고 마지막 프로젝트에서 실제로 코드를 통해 실습을 해보도록 하겠습니다.
2022년 10월 31일