2. Scrapy shell > 2-2. Scrapy shell에서 CSS Selector와 XPath로 데이터 가져오기
Scrapy shell에서 CSS Selector와 XPath로 데이터 가져오기
CSS Selector와 XPath를 사용해 데이터를 가져오는 법을 배워보겠습니다. 기본문법은 다음과 같습니다.
- response.css('CSS Selector 경로') : CSS Selector로 데이터 가져오기
- response.xpath('XPath 경로') : XPath로 데이터 가져오기
💡 CSS Selector vs. XPath
| 설명 | CSS Selector: response.css() | XPath: response.xpath() |
|---|---|---|
| 데이터 하나만 가져오기 | ('경로').get() | ('경로').get() |
| 데이터 전체를 리스트로 가져오기 | ('경로').getall() | ('경로').getall() |
| 태그 없이 내용(텍스트)만 추출 | 경로 뒤에 ::text 붙이기 | 경로 뒤에 /text() 붙이기 |
| 속성값(name, href 등) 추출 | 경로 뒤에 ::attr(속성값) 붙이기 | 경로 뒤에 //@속성값 붙이기 |
💡 개념잡기: 웹페이지 데이터 경로 가져오는 법
웹페이지에서 ctrl+shift+c를 누르고 원하는 데이터 클릭하면 개발자 도구(F12)에 경로 부분이 표시됩니다.
그 경로에 속하는 가장 가장 가까운 div부터 내려오는 형식으로 경로를 적어 내려가면 good!
a. 마우스 오른쪽 클릭 > Copy를 해도 좋지만 가끔 오류가 뜹니다.
b. 예: div id 속성이 csdm scrapy인 경우
- response.css('div#csdm.scrapy ul li a::text').getall()
- response.xpath('//*[@id="csdm.scrapy"]/ul/li/a/text()').getall()
+) ctrl + F : 페이지 소스에서 코드 검색 단축키
배운 내용을 바탕으로 다음 뉴스 기사의 제목을 크롤링해보겠습니다.
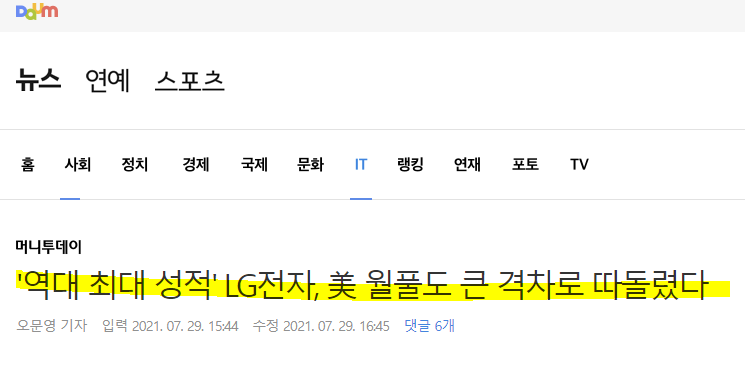
위의 기사에서 개발자 도구(F12)를 열었을 때, 기사 제목 부분에 해당하는 경로는 아래와 같이 나타납니다.
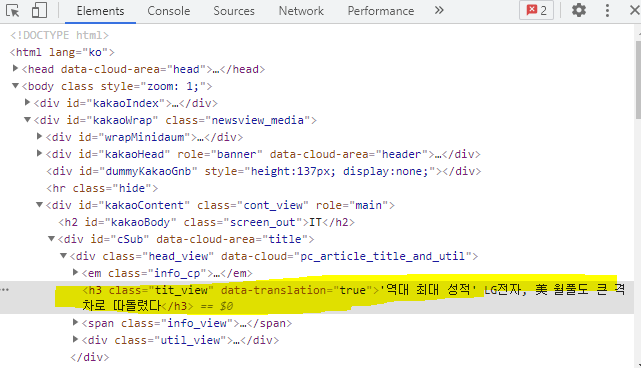
-
예제 1) CSS Selector 경로
다음과 같이 CSS Selector 경로를 입력해주면 기사 제목이 출력됩니다.
#기사 제목 데이터 가져오기 response.css('#cSub > div > h3').get() # 여기서 > 은 직계 자식 태그를 의미 #기사 제목 데이터 태그 없이 텍스트만 가져오기 response.css('#cSub > div > h3::text').get() # 혹은 response.css('div.head_view h3.tit_view::text').get()
📖 참고하기: CSS Selector 문법
CSS Selector 문법을 작성하는게 어렵게 느껴지면 아래 글을 참고해보세요.
-
예제 2) XPath 경로
다음과 같이 XPath 경로를 입력해주면 기사 제목이 출력됩니다.
# 기사 제목 데이터 가져오기 response.xpath('//*[@id="cSub"]/div/h3').get() # 기사 제목 데이터 태그 없이 텍스트만 가져오기 response.xpath('//*[@id="cSub"]/div/h3/text()').get()
단, 한 가지 주의할 점!
위의 XPath 코드를 보면 '//*[@id="cSub"]/div/h3' 와 같이 작은 따옴표('')가 쳐져있죠?
XPath 안의 따옴표('')와 XPath 경로를 둘러싼 따옴표('')의 종류가 같을 경우, 아래와 같이 구문 오류가 발생하게 됩니다.
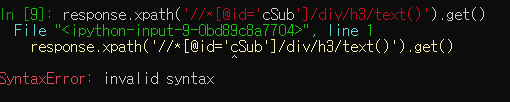
따라서 각각을 작은따옴표(')와 큰따옴표(")로 구분해서 코드를 쳐주어야 합니다.
📖 참고하기: XPath 기본 개념
-
XPath(XML Path Language)란?
XPath란 'XML 문서의 특정 요소나 속성에 접근하기 위한 경로를 지정하는 언어'를 의미합니다.
(참고로 BeautifulSoup는 XPath를 통한 크롤링을 지원하지 않습니다.)
- XPath 문법 맛보기: [잔재미코딩] XPATH 이용하기
-
단, XPath는 주로 과거에 사용하던 경로입니다. 따라서 본 커리큘럼에서는 CSS Selector 경로만을 사용하여 데이터를 가져올 예정입니다. Scrapy shell을 적극 활용하여 CSS Selector를 이용한 경로가 잘 가져와졌는지 확인해보시길 바랍니다 😉
2022년 9월 24일