4. Spider(크롤러) 만들기 > 4-1. Spider(크롤러) 만들기
Spider(크롤러) 만들기
이제 본격적인 실습을 통해 Spider(크롤러) 생성부터 데이터 후처리까지 학습해보도록 하겠습니다.
이전(1주차)에도 말씀드렸듯이 class에 관한 내용이 필수적으로 뒷받침되어야 하기 때문에 기억이 나지 않으시는 분들은 아래 링크를 통해 클래스, 객체, 메서드 등 용어를 중심으로 복습하시고 학습해주시기를 권장드립니다 🙂
코사다마의 웹크롤링 심화 커리에서는 11번가 사이트 크롤링을 통해 실습이 진행되며, 이번 실습에서는 Scrapy 프로젝트 파일을 하나하나 파헤쳐 볼 예정입니다.
📢 유의사항
'4. Spider(크롤러) 만들기' ~ '6. [프로젝트] 11번가 사이트 카테고리별 베스트 상품 크롤링'(2~3주차)까지 실습 및 프로젝트에 있어 py 파일 수정을 jupyter notebook으로 합니다.
원래는 텍스트 에디터(코드 편집 프로그램)를 사용해야 되는데, 일단은 Scrapy 학습에 초점을 두기로 했어요. (주피터 노트북은 텍스트 에디터가 아닙니다!!!)
대표적인 텍스트 에디터로는 Visual Studio Code(VS Code), Sublime Text, Atom 등이 있습니다. 이후(4주차)에 VS Code의 기초적인 사용법을 익혀볼 예정이니 기대해 주세요 😊
📖 살펴보기: 텍스트 에디터 종류
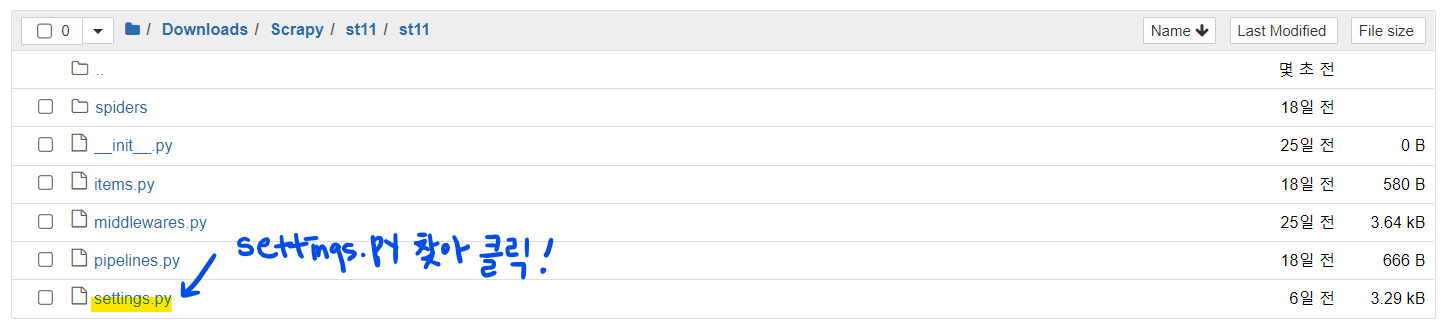
시작하기 앞서 jupyter notebook으로 settings.py를 열어 한 가지 설정을 추가하겠습니다.
📖 settings.py 여는 법을 모른다면...
- jupyter notebook을 실행합니다.
- 자신이 Scrapy 프로젝트를 만든 폴더로 이동합니다. (예: Downloads > Scrapy)
- settings.py를 찾아 클릭합니다.
DOWNLOAD_DELAY = 1 # 페이지 다운로드 간격을 1초로 지정

이 설정을 해주지 않으면 페이지 다운로드 간격이 0초라 웹사이트에 부하를 걸게 될 수 있습니다. 사이트 관리자의 워라밸을 위해 해당 설정을 꼭 저장해 줍시다 👨💻
그럼 본격적으로 Spider(크롤러)를 생성해 봅시다.
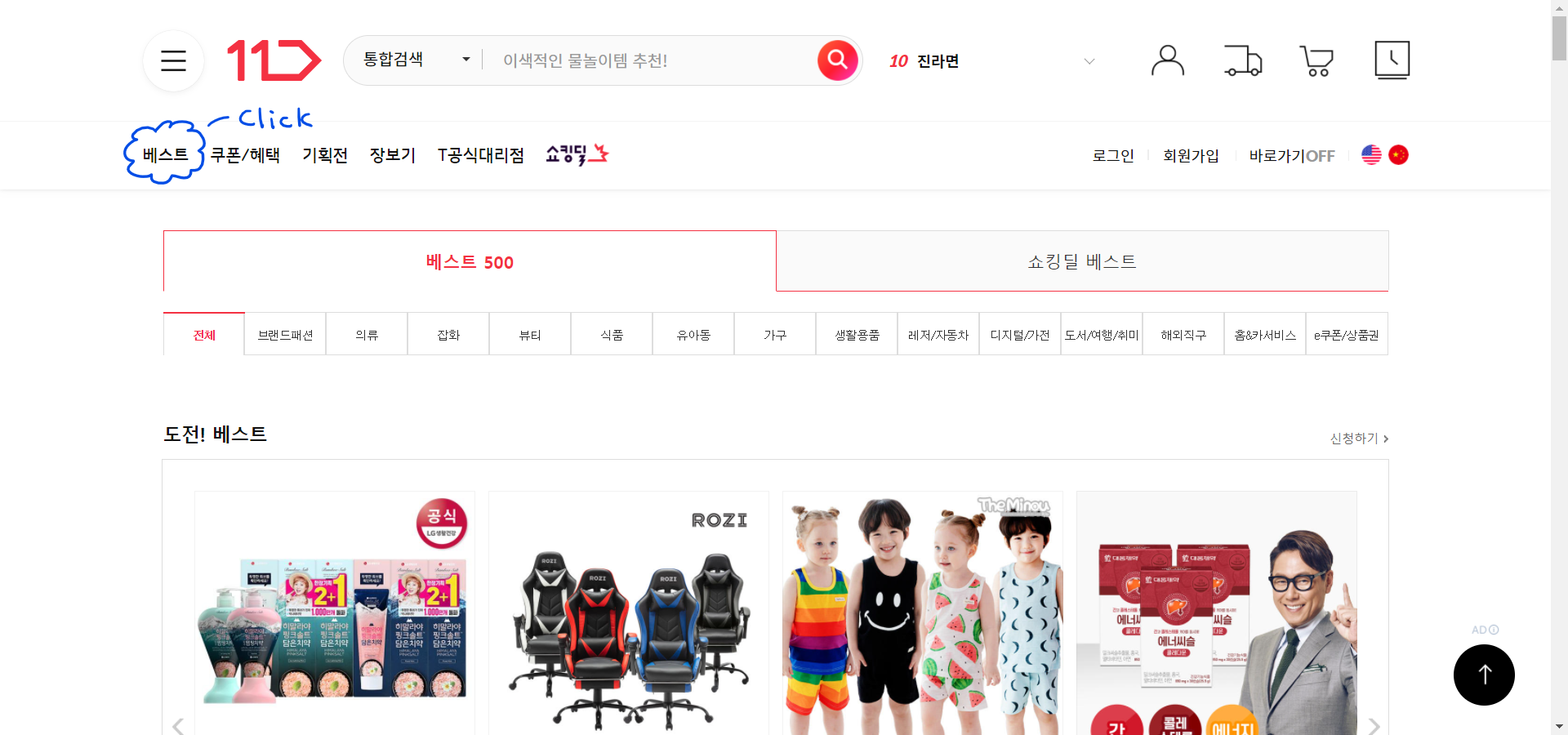
11번가 사이트의 베스트 카테고리 - 전체 부문를 크롤링하는 spider(=크롤러)를 만들어보겠습니다.
#명령어 - 터미널에 입력
scrapy genspider <spider 이름> "크롤링 페이지 주소"
# 예: 11번가 베스트 카테고리 spider 생성
# 반드시 경로 이동한 뒤!!! spider 만들어 주세요!!!!!!
cd Downloads\Scrapy\st11 # 본인의 프로젝트 디렉토리로 이동
scrapy genspider st11_all "www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain"

(본 교안에서는 Spider(크롤러)가 이미 만들어진 상태라 출력되는 메세지가 다릅니다. 'create spider '크롤러 이름' using template 'basic' in module:' 이 출력되면 성공!)
이때, 주의할 점!
-
spider 이름: st11_all
프로젝트명과 동일하게 spider 이름을 지을 수 없음. (Cannot create a spider with the same name as your project)
-
크롤링 페이지 주소: 베스트 카테고리 - 전체 부문
https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain
(크롤링 페이지 주소에서 https:// 는 빼줍니다. 이유는 이후 '4-2. Spider 클래스'에서 설명드릴게요.)
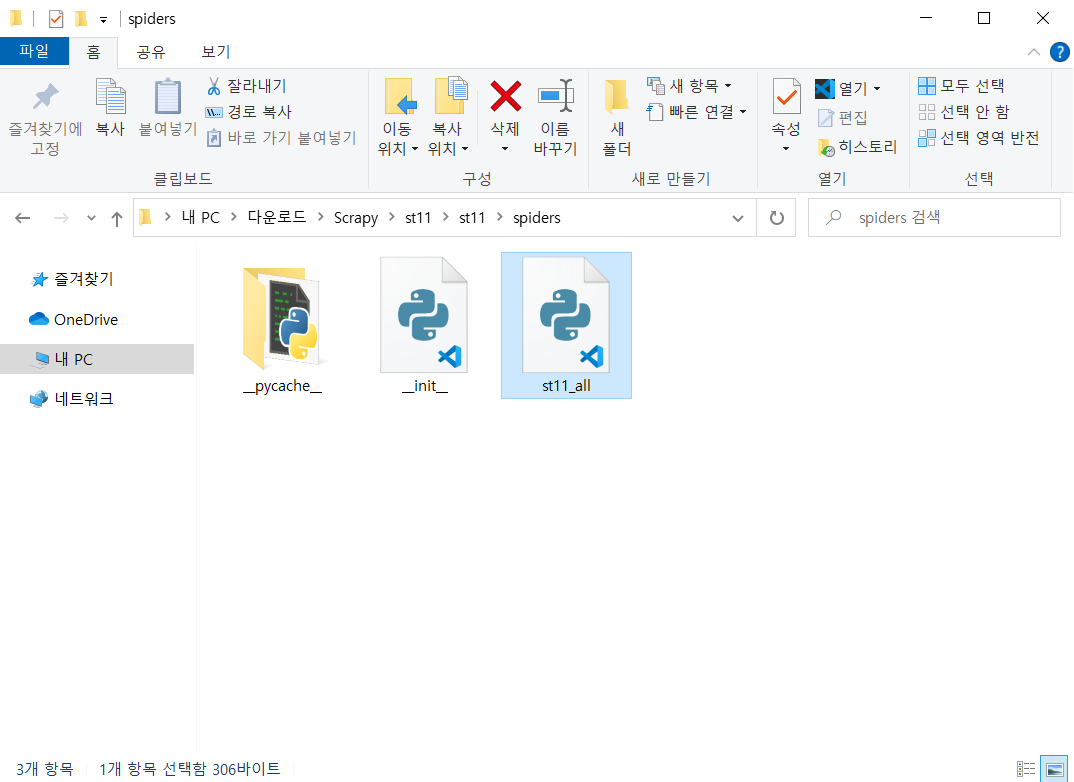
spiders 디렉토리 안에 st11_all.py가 생성된 것을 확인할 수 있습니다.
2022년 9월 24일