웹 크롤링 심화
0. 추천 학습 가이드
3. Scrapy 프로젝트 생성
6. [프로젝트] 11번가 사이트 카테고리별 베스트 상품 크롤링
커리 개발: 김민석 신윤진 송혜민
5. 크롤링 데이터 다루기 > 5-4. 데이터 후처리하기
데이터 후처리하기
Item의 데이터를 파일로 저장하기 전 원하는 대로 데이터를 처리할 수 있습니다.
이때 사용하는 것이 Item Pipeline(이하 Pipeline) 입니다.
💡 Pipeline
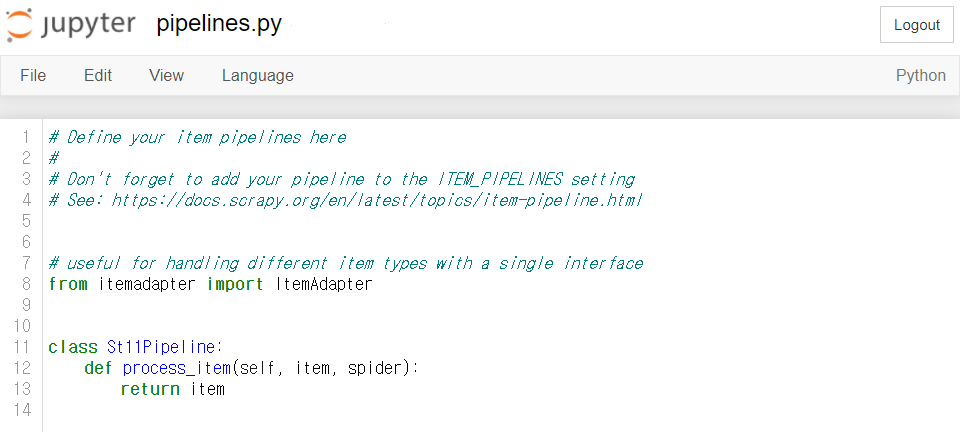
Pipeline은 process_item() 이라는 특정한 이름의 메서드를 가진 클래스입니다.
프로젝트를 처음 생성했을 때 pipelines.py에 클래스의 기본 형태가 아래처럼 작성되어 있어요.
spider의 콜백 함수 parse() 에서 yield한 Item은 반드시 Pipeline의 process_item() 메서드를 거쳐가게 됩니다.
따라서 process_item() 메서드를 통해 원하는 Item은 return 해주고, 원하지 않는 Item은 raise DropItem을 통해 필터링하는 것이 가능합니다.
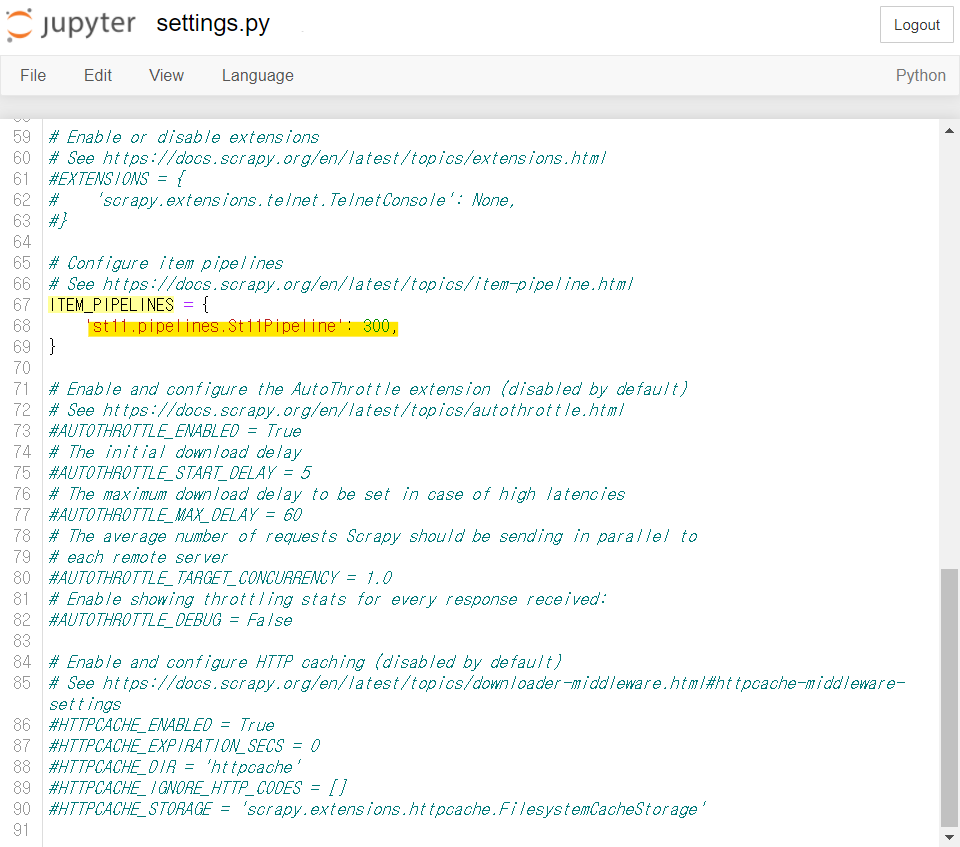
# 실제 파일 수정은 하지 말고 눈으로만 읽을 것! # 예: 상품가격(판매가격)이 10,000원 이상인 경우에만 상품가격 크롤링 from itemadapter import ItemAdapter from scrapy.exceptions import DropItem class St11Pipeline: def process_item(self, item, spider): if int(item['price']) > 10000: return item else: raise DropItem('dropitem', item)단, Pipeline을 사용하기 위해서는 settings.py에서 다음 코드를 찾아 주석(#)을 없애주어야 합니다.
#settings.py ITEM_PIPELINES = { 'st11.pipelines.St11Pipeline': 300, # 숫자(0 ~ 1000 입력)는 Pipeline의 적용 순서를 의미 } # 숫자가 작은 것부터 차례대로 적용됨
Scrapy는 웹페이지 다운로드 처리, spider의 콜백 함수 처리 등의 다양한 확장 기능을 제공하는데요. 이러한 기능은 프로젝트의 middleware.py에서 설정할 수 있습니다. middleware.py에 대한 내용은 본 교안에서는 다루지 않습니다. 분량이 매우 방대할뿐더러 코사다마의 커리큘럼만으로는 이해하기 어렵기 때문입니다. 궁금하신 분들은 Scrapy 공식 사이트의 관련 문서를 참고해보세요.
- [Scrapy] Downloader Middleware - 웹페이지 다운로드 처리
- [Scrapy] Spider Middleware - spider 콜백 함수 처리
마지막으로 업데이트 된 날짜:
2022년 9월 24일
2022년 9월 24일