웹 크롤링 심화
0. 추천 학습 가이드
3. Scrapy 프로젝트 생성
6. [프로젝트] 11번가 사이트 카테고리별 베스트 상품 크롤링
커리 개발: 김민석 신윤진 송혜민
6. [프로젝트] 11번가 사이트 카테고리별 베스트 상품 크롤링 > 6-4. 메인 카테고리의 베스트 상품 크롤링
메인 카테고리의 베스트 상품 크롤링
이제 준비가 완료되었으니 본격적으로 메인 카테고리를 크롤링 하는 코드를 하나하나 작성해보겠습니다. 먼저 각 메서드를 하나하나 살펴보고, 전체 코드를 이해해 봅시다.
그전에, 아래 코드를 보면 response.css(quiz)라고 적혀있는 코드들이 있습니다. 이 부분은 items.py에서 생성한 필드에 저장할 데이터들이 위치한 css 선택자 경로에 해당하는 내용인데, 1주차 과제에서 Scrapy shell로 찾은 경로를 순서대로 채워 넣어주시기만 하면 됩니다!
#st11_best.py: 1번(주소 불러오기)
# 주소 request하고 callback하는 메서드
def start_requests(self):
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo=0",
callback=self.parse_mainpages) # 주소를 아래 메서드로 보내고, response 처리 요청
# 메인 카테고리
def parse_mainpages(self, response):
print("parse_mainpages") # callback이 잘 되었는지 확인하기 위함
category_names = response.css(quiz:메인 카테고리명의 css 선택자 경로).getall() # 메인 카테고리의 이름을 리스트로 불러오기
for idx, name in enumerate(category_names):
# 이제 각 메인 카테고리 사이트별(No=)로 response 처리 요청을 보낼 것임
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo="+str(idx),
callback=self.parse_items, # parse_items 메서드를 호출해서 실행
meta={'maincategory_name':category_names[idx], 'subcategory_name':'All'}) # 이 데이터도 내려보내줌
#st11_best.py: 2번(데이터 불러오기)
def parse_items(self, response):
print('parse_items', response.meta['maincategory_name'], response.meta['subcategory_name']) # 잘 가져와 졌는지 확인
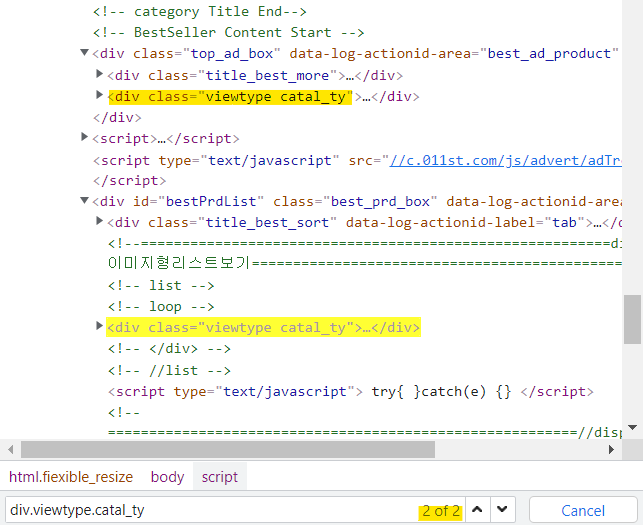
best_items = response.css('div.viewtype.catal_ty') # 베스트 상품이 위치한 메인 선택자 경로
for idx, item in enumerate(best_items[1].css('li')): # 같은 선택자 경로가 "도전! 베스트"라고 하나 더 있어서, 두번째 선택자 경로로 지정해줘야 함
# div의 class가 viewtype.catal_ty인 것 중 2번째 내부의 li들을 이용(&)
doc = St11Item()
ranking = idx + 1 # 랭킹은 인덱스에 1을 더해주면 됨
# 아래 빈칸에는 베스트 상품의 이름에 해당하는 css 선택자 경로를 넣어주면 됨. response.css가 아닌 item.css임을 주의!
title = item.css(quiz:베스트 상품명의 css 선택자 경로).get().strip() # .strip 함수는 pipelines.py에서 해줘도 가능함. 아래에서 설명
ori_price = item.css(quiz:기존가격의 css 선택자 경로).get()
dis_price = item.css(quiz:할인가격의 css 선택자 경로).get() # 반복문이니 getall()이 아닌 get()을 사용함
if ori_price == None: # 할인하지 않는 상품은 기존 가격 데이터가 없으니 할인 가격과 같게 정해줌
ori_price = dis_price
ori_price = ori_price.replace(',','').replace('원','') # 이후 분석의 편리를 위해 콤마와 '원'을 삭제
dis_price = dis_price.replace(',','').replace('원','') # 이것도 pipelines.py에서 후처리 가능함
doc['main_category_name'] = response.meta['maincategory_name'] # 위 메서드에서 가져온 데이터를 Item(필드)에 넣어줌
doc['sub_category_name'] = response.meta['subcategory_name']
doc['ranking'] = ranking
doc['title'] = title
doc['ori_price'] = ori_price
doc['dis_price'] = dis_price
yield doc # 마지막으로 Item에 데이터 저장
-
(&) - 개발자 도구(F12)로 반드시 검색해보기
#st11_best.py: 최종 코드
import scrapy
from st11.items import St11Item
class St11BestSpider(scrapy.Spider):
name = 'st11_best'
def start_requests(self):
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo=0",
callback=self.parse_mainpages)
def parse_mainpages(self, response):
print("parse_mainpages")
category_names = response.css(quiz:메인 카테고리명의 css 선택자 경로).getall()
for idx, name in enumerate(category_names):
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo="+str(idx),
callback=self.parse_items,
meta={'maincategory_name':category_names[idx], 'subcategory_name':'All'})
def parse_items(self, response):
print('parse_items', response.meta['maincategory_name'], response.meta['subcategory_name'])
best_items = response.css('div.viewtype.catal_ty')
for idx, item in enumerate(best_items[1].css('li')):
doc = St11Item()
ranking = idx + 1
title = item.css(quiz:베스트 상품명의 css 선택자 경로).get().strip()
ori_price = item.css(quiz:기존가격의 css 선택자 경로).get()
dis_price = item.css(quiz:할인가격의 css 선택자 경로).get()
if ori_price == None:
ori_price = dis_price
ori_price = ori_price.replace(',','').replace('원','')
dis_price = dis_price.replace(',','').replace('원','')
doc['main_category_name'] = response.meta['maincategory_name']
doc['sub_category_name'] = response.meta['subcategory_name']
doc['ranking'] = ranking
doc['title'] = title
doc['ori_price'] = ori_price
doc['dis_price'] = dis_price
yield doc
만약 실행이 잘 되었다면 이런 결과가 터미널에 쭈~욱 나올 겁니다. 직접 사이트의 내용과 맞는지 대조해보세요 🧐
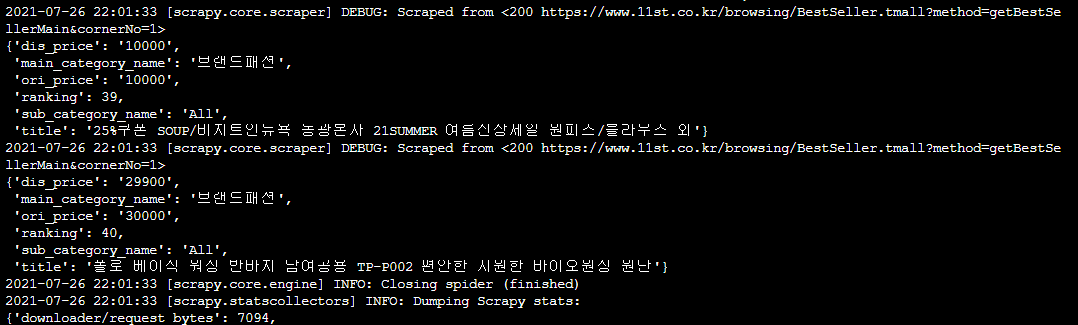
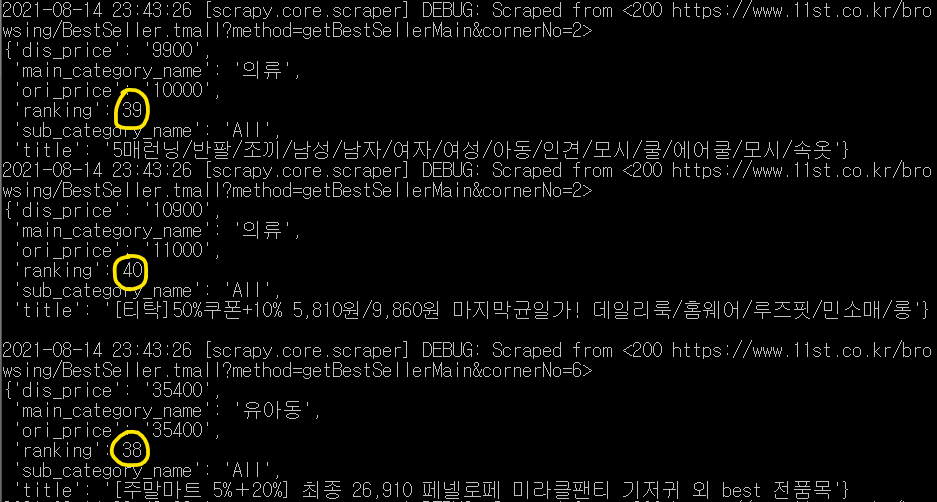
참고로 실행 화면에서 랭킹이나 카테고리 등이 순서대로 출력되지 않을 수 있습니다. 데이터와 item들의 순서가 뒤죽박죽인 이유는, Scrapy가 크롤링 할 때 여러 개의 spider(크롤러)가 작동하기 때문입니다. 여러 개의 spider가 크롤링 하면서 속도는 빨라지지만, 빠른 순서대로 크롤링하기 때문에 크롤링하여 출력, 저장되는 순서는 섞이게 되는 것이죠.
마지막으로 업데이트 된 날짜:
2022년 11월 18일
2022년 11월 18일