6. [프로젝트] 11번가 사이트 카테고리별 베스트 상품 크롤링 > 6-6. 데이터 후처리 및 저장
데이터 후처리 및 저장
하나의 카테고리 당 최대 500개의 베스트 상품이 있고 크롤링 하면 2주차처럼 각각 40개씩 데이터가 나올 텐데, 저장하기에는 너무 많으니 후처리를 통해 랭킹 1위~5위까지만 저장을 해봅시다.
#pipelines.py
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
class St11Pipeline:
def process_item(self, item, spider):
if int(item['ranking']) <= 5: # 랭킹이 5보다 작거나 같으면
return item # 그대로 return
else:
raise DropItem("순위권 밖", item) # 아니면 raise error
pipelines.py를 수정했으니 설정으로 pipeline을 사용한다고 정의해줘야겠죠? 그리고 데이터 저장을 예쁘게 하기 위해 저장될 아이템들의 순서를 정해줍시다.
#settings.py
ITEM_PIPELINES = { # 주석(#)만 없애주면 됨
'st11.pipelines.St11Pipeline': 300,
}
# 아이템 출력 순서 설정: 직접 코드 추가
FEED_EXPORT_FIELDS = ['main_category_name', 'sub_category_name', 'ranking', 'title', 'ori_price', 'dis_price']
❓ 궁금해요: 아이템 순서를 지정하지 않으면 어떻게 되나요?
이렇게 됩니다 ☹
이제 마지막으로 크롤링한 데이터를 저장하고, 잘 크롤링 되었는지 사이트와 몇 개 비교하며 확인해봅시다.
#터미널
# DOWNLOAD_DELAY 설정을 하면 너무 느려질 수 있으니, 반드시 주석처리 한 뒤 실행할 것!!!
scrapy crawl st11_best -o st11_best.csv -t csv
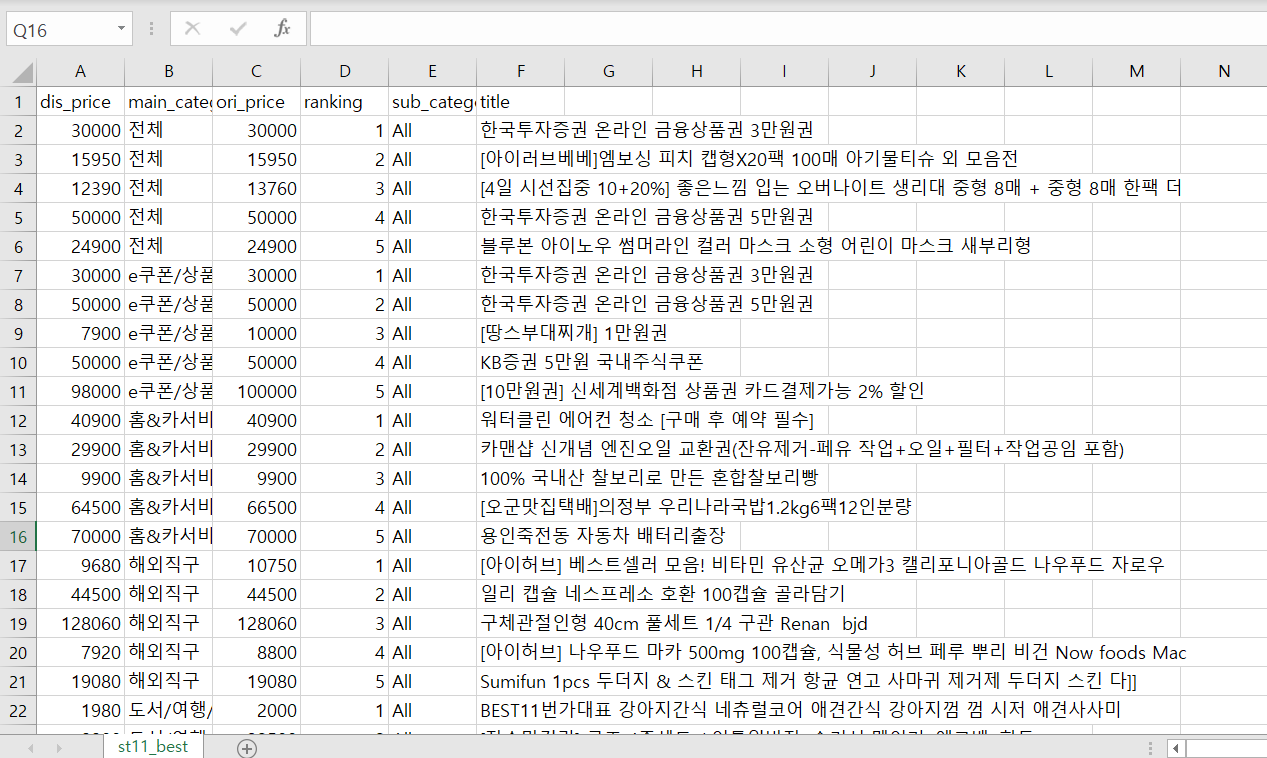
명령을 수행한 디렉토리에 파일이 잘 저장되었는지 확인해보시기 바랍니다. 저장한 결과 파일의 데이터 수는 205(전체 카테고리 개수) * 5(순위) = 1025(전체 데이터 수)여야 하는데 숫자가 달라서 파이썬에서 pd.read_csv로 살펴보니, '홈&카서비스'의 서브 카테고리에서 랭킹이 5위까지 없는 서브 카테고리가 있었습니다. 제가 크롤링할 당시 사이트에서 직접 세보니 17개의 데이터가 부족했고 csv 파일의 첫번째 줄은 아이템명(컬럼명)이니 csv 파일은 1009줄로 알맞게 저장되어 있었습니다.
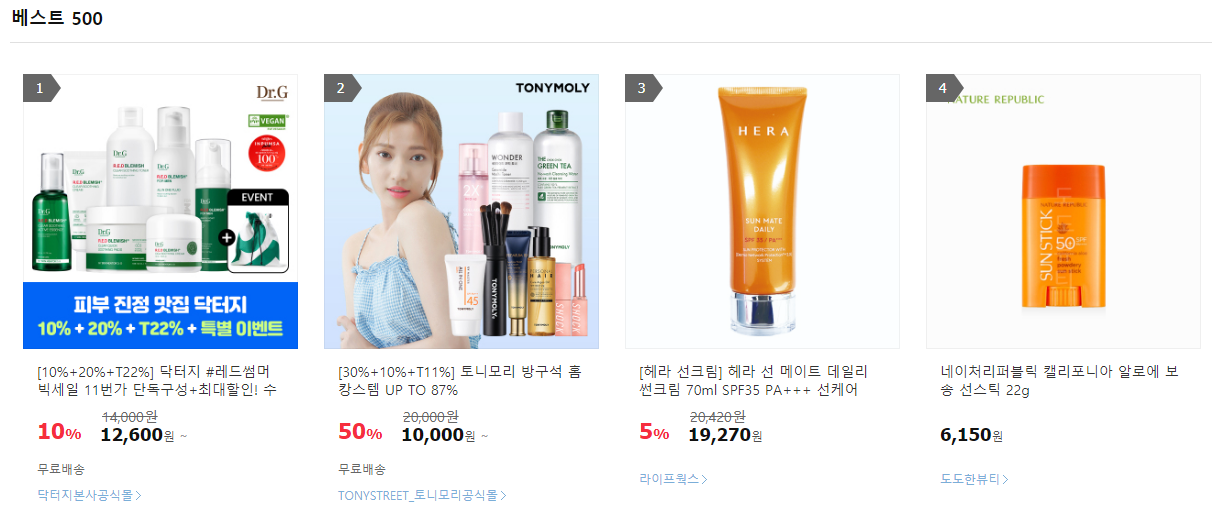
마지막으로, 파일을 확인해보면 저장이 잘 된 것을 확인할 수 있었습니다. 그리고 무작위로 정한 (뷰티, 선케어) 항목의 베스트 상품 내용과 csv 파일에 저장된 내용을 직접 대조해보면 정보가 정확히 일치하여 잘 크롤링 된 것을 확인할 수 있습니다 😆

2022년 9월 24일