웹 크롤링 심화
0. 추천 학습 가이드
3. Scrapy 프로젝트 생성
6. [프로젝트] 11번가 사이트 카테고리별 베스트 상품 크롤링
커리 개발: 김민석 신윤진 송혜민
6. [프로젝트] 11번가 사이트 카테고리별 베스트 상품 크롤링 > 6-5. 메인 카테고리, 서브 카테고리의 베스트 상품 크롤링
메인 카테고리, 서브 카테고리의 베스트 상품 크롤링
이제 서브 카테고리의 베스트 상품까지 크롤링해봅시다. 위의 코드를 그대로 가져오면서 중간 부분을 약간만 손볼 예정입니다. 어디가 어떻게 바뀌었는지, 메서드끼리 어떻게 연결되어 있는지 확인해보면서 수정해보세요!
서브 카테고리 주소는 메인 카테고리 주소 + "&dispCtgrNo=1001295"의 형식입니다. 뒤의 서브 카테고리 고유번호(1001296)를 알려주는 css 선택자 경로를 html 파일에서 찾아내고, 그 주소를 크롤링 하는 코드를 더해주기만 하면 되겠네요!
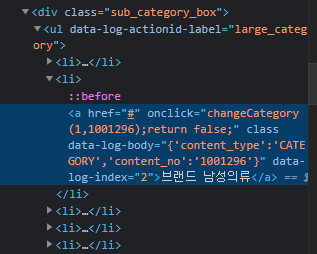
메인 카테고리와 서브 카테고리 주소를 이용할 때 아래의 css 선택자 경로에서 a의 onclick이라는 속성을 이용할 예정입니다. 참고하고 코드를 확인해보세요.
- 예: (브랜드패션, 브랜드 남성의류) == (1, 1001296) == (메인 카테고리 고유번호, 서브 카테고리 고유번호)
#st11_best.py: 1번(메인 카테고리 주소 불러오기)
def parse_mainpages(self, response):
print("parse_mainpages")
category_names = response.css(quiz:메인 카테고리명의 css 선택자 경로).getall()
for idx, name in enumerate(category_names):
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo="+str(idx),
callback=self.parse_items,
meta={'maincategory_name':category_names[idx], 'subcategory_name':'All'})
# 이 위까지는 이미 있던 코드
# 이제는 서브 카테고리 크롤링을 위한 request도 추가해주자: 위 반복문과 거의 비슷함. callback과 meta만 약간의 차이
for idx, name in enumerate(category_names):
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo="+str(idx),
callback=self.parse_subcategory, # 서브카테고리를 크롤링하는 메서드로
meta={'maincategory_name':category_names[idx],'index':idx}
)
#st11_best.py: 2번(서브 카테고리 주소 불러오기)
def parse_subcategory(self, response):
print('parse_subcategory', response.meta['maincategory_name']) # meta로 전달받은 데이터 확인
subcategory_names = response.css(quiz:서브 카테고리명의 css 선택자 경로).getall() # 전체 서브 카테고리 이름을 리스트로
# 아쉽게도 서브 카테고리 정보는 메인 카테고리 별로 명확히 나뉘어져 있지 않아서 다른 정보를 이용해야함
# 주소에 들어가는 (메인 카테고리 고유번호, 서브 카테고리 고유번호) 값을 위의 사진에서 나온 선택자 경로에서 확인할 수 있으니 이 정보를 이용
subcategory_lists = response.css('div.sub_category_box li a::attr("onclick")').re('\(.*\)') # 데이터 중 괄호 안의 정보를 크롤링해오기
subcategory_idcs = []
for i in subcategory_lists:
# category_lists 내 변수들이 문자열로 되어 있으므로 튜플 형태로 바꿔주기 위함
# i는 '(1,1001296)'라는 문자열 형태, 바꾸고자 하는 튜플 형태는 (1,1001296)
if i[2] == ',':
subcategory_idcs.append((int(i[1]),int(i[3:-1])))
else:
subcategory_idcs.append((int(i[1:3]),int(i[4:-1])))
for idx, sub in enumerate(subcategory_idcs): # idx = 부여된 인덱스 번호, sub = (메인 카테고리 고유번호, 서브 카테고리 고유번호) 형태의 튜플
if sub[0] == response.meta['index']: # 만일 메인 카테고리 고유번호 == meta로 가져온 메인 카테고리 인덱스 번호면: 메인 카테고리가 일치하니 서브 카테고리 정보를 가져옴
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo=" + str(sub[0]) + "&dispCtgrNo=" + str(sub[1]),
callback=self.parse_items, # 메인 카테고리와 마찬가지로 크롤링 하는 메서드로!
meta={'maincategory_name':response.meta['maincategory_name'],
'subcategory_name':subcategory_names[idx]}
)
else: # 반면, 서브 카테고리가 메인 카테고리에 속하지 않는 경우, 즉 메인 카테고리 인덱스 번호가 둘이 서로 다른 경우는 그냥 넘어감.
continue
#st11_best.py: 최종
import scrapy
from st11.items import St11Item
class St11BestSpider(scrapy.Spider):
name = 'st11_best'
def start_requests(self):
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo=0",
callback=self.parse_mainpages)
def parse_mainpages(self, response):
print("parse_mainpages")
category_names = response.css(quiz:메인 카테고리명의 css 선택자 경로).getall()
for idx, name in enumerate(category_names):
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo="+str(idx),
callback=self.parse_items,
meta={'maincategory_name':category_names[idx], 'subcategory_name':'All'})
for idx, name in enumerate(category_names):
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo="+str(idx),
callback=self.parse_subcategory,
meta={'maincategory_name':category_names[idx],'index':idx}
)
def parse_subcategory(self, response):
print('parse_subcategory', response.meta['maincategory_name'])
subcategory_names = response.css(quiz:서브 카테고리명의 css 선택자 경로).getall()
subcategory_lists = response.css('div.sub_category_box li a::attr("onclick")').re('\(.*\)')
subcategory_idcs = []
for i in subcategory_lists:
if i[2] == ',':
subcategory_idcs.append((int(i[1]),int(i[3:-1])))
else:
subcategory_idcs.append((int(i[1:3]),int(i[4:-1])))
for idx, sub in enumerate(subcategory_idcs):
if sub[0] == response.meta['index']:
yield scrapy.Request(url="https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain&cornerNo=" + str(sub[0]) + "&dispCtgrNo=" + str(sub[1]),
callback=self.parse_items,
meta={'maincategory_name':response.meta['maincategory_name'],
'subcategory_name':subcategory_names[idx]}
)
else:
continue
# 메인 카테고리, 서브 카테고리의 정보를 모두 크롤링하는 메서드. 코드는 처음과 동일
def parse_items(self, response):
print('parse_items', response.meta['maincategory_name'], response.meta['subcategory_name'])
best_items = response.css('div.viewtype.catal_ty')
for idx, item in enumerate(best_items[1].css('li')):
doc = St11Item()
ranking = idx + 1
title = item.css(quiz:베스트 상품이름의 css 선택자 경로).get().strip()
ori_price = item.css(quiz:할인전가격의 css 선택자 경로).get()
dis_price = item.css(quiz:할인된가격의 css 선택자 경로).get()
if ori_price == None:
ori_price = dis_price
ori_price = ori_price.replace(',','').replace('원','')
dis_price = dis_price.replace(',','').replace('원','')
doc['main_category_name'] = response.meta['maincategory_name']
doc['sub_category_name'] = response.meta['subcategory_name']
doc['ranking'] = ranking
doc['title'] = title
doc['ori_price'] = ori_price
doc['dis_price'] = dis_price
yield doc
# 메인 카테고리 크롤링 과정: start_requests -> parse_mainpages -> parse_items
# 서브 카테고리 크롤링 과정: start_requests -> parse_mainpages -> parse_subcategory -> parse_items
# ㄴ 서브카테고리가 메인 카테고리 안에 있기 때문에 서브 카테고리라도 메인 카테고리를 거쳐가야 함.
위 코드를 작성 후 실행한 뒤에, 약 30초 정도 아까 본 실행 결과가 쭉 나올 겁니다. 이제는 성공적으로 크롤링 되었는지 확인하기 전에 데이터 후처리와 설정을 수정해봅시다.
마지막으로 업데이트 된 날짜:
2022년 9월 24일
2022년 9월 24일