4. Spider(크롤러) 만들기 > 4-2. Spider 클래스
Spider 클래스
jupyter notebook으로 st11_all.py를 열어보면 다음과 같습니다.
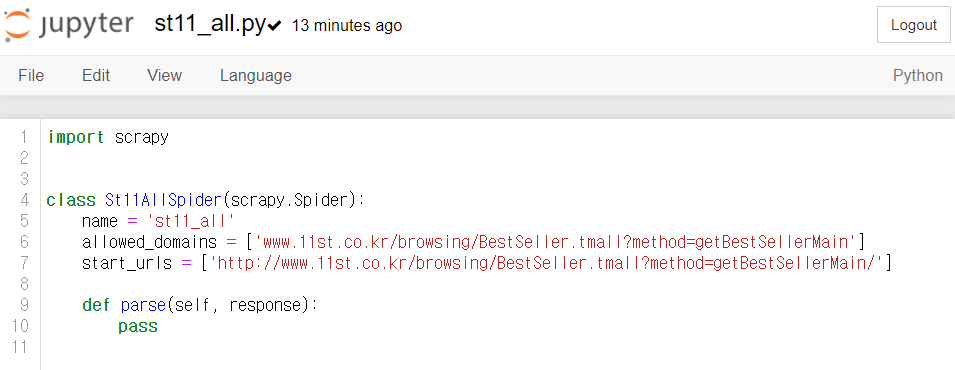
Scrapy의 spider는 scrapy.Spider를 상속받는 클래스입니다. 클래스 이름은 자유롭게 수정해도 되지만, 반드시 scrapy.Spider를 상속받아야 합니다.
*클래스에 대한 내용이 기억나지 않는다면 이전(1주차)의 커리큘럼 내용과 다음 자료를 반드시 복습해주세요.
St11AllSpider 클래스에는 3가지 속성(name, allowed_domains, start_urls)과 parse() 메서드가 있습니다.
-
name : spider의 이름을 설정하는 속성
scrapy genspider 명령어를 입력했을 때 자동으로 입력된 것이며, 이후 spider 실행에 입력된 이름이 사용됩니다.
-
allowed_domains : 크롤링 페이지 주소의 리스트를 지정하는 속성
마구잡이로 링크를 이동하다 보면 예상하지 못한 웹페이지에 접근하는 경우가 발생합니다. 이런 경우를 막고자 허용된 주소 이외에는 크롤링 하지 못하도록 하는 속성입니다.
저희 실습에서는 삭제해도 무관하나, 불특정 다수의 웹사이트를 대상으로 자유롭게 크롤링하는 경우를 제외하면 지정하는 것을 권장합니다.
# 예 allowed_domains = ['www.11st.co.kr'] # 11번가 내의 여러 페이지를 크롤링하고자 한다면 아래처럼 입력 # 의미: allowed_domains로 시작하는 url이 아니면 접근하지 말 것 -
start_urls : 크롤링할 페이지 주소를 나타내는 속성
주소 목록을 리스트 혹은 튜플 형식으로 지정합니다. 저희는 11번가 베스트 카테고리 하나만 입력하지만 여러 개의 주소를 지정할 수 있습니다.
# 예 # 대한민국 쇼핑몰 사이트를 크롤링하고자 하면 start_urls = ['http://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain', 'https://www.gmarket.co.kr', 'http://www.auction.co.kr', 'https://www.coupang.com' ]위에서 spider를 만들 때 크롤링 페이지 주소를 https:// 를 제외하고 입력했는데요. 그 이유는 start_urls 에 기본적으로 http:// 가 입력되어 있어 https:// 가 중복 기입되기 때문입니다.
# 예 # 주소 끝의 '/(슬래시)' 지워줄 것! start_urls = ['[http://https://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain](http://www.11st.co.kr/browsing/BestSeller.tmall?method=getBestSellerMain/)'] -
parse() : 추출한 웹페이지 처리를 위한 콜백 함수
response에 start_urls에 지정된 주소의 서버에서 넘겨받은 응답 데이터가 크롤링 결과로 담기기 때문에, response를 반드시 인자로 받아야 합니다.
💡 개념잡기: 콜백 함수(callback function)란?
- 관련 영상(~2:27까지 시청)
- 요약: 사용자에 의해 직접 호출되는 것이 아닌 다른 함수에서 호출되는 함수
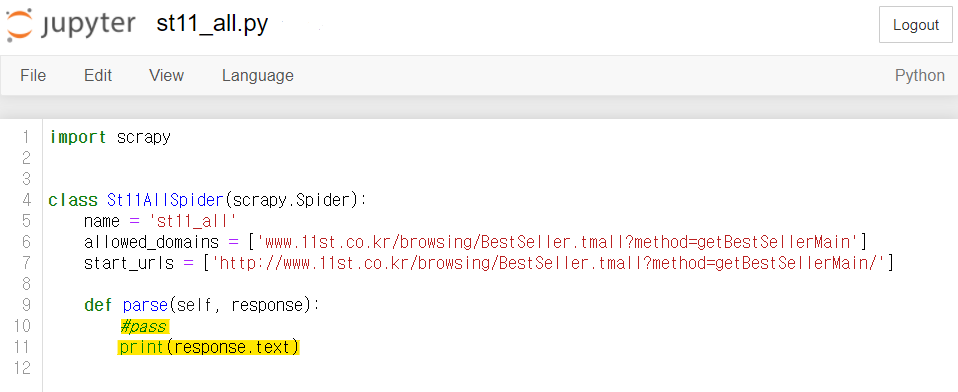
response에 응답 데이터가 제대로 담기는지 확인해봅시다. st11_all.py를 살짝 수정해 주세요.
#st11_all.py
def parse(self, response):
#pass
print(response.text) # response.text에 크롤링 된 데이터가 담겨있음
spider를 실행해봅니다.
#명령어 - 터미널에 입력
scrapy crawl <spider 이름>
# 예: 11번가 베스트 카테고리 크롤링
scrapy crawl st11_all

출력된 메세지를 잘 살펴보면 'DEBUG: Forbidden by robots.txt:' 라는 문장을 찾을 수 있습니다.
웹페이지 정보도 크롤링되지 않은 것 같아요. 이유가 무엇일까요?
(*그 이유는 이후(4-2. Robots.txt(로봇 배제 표준)) 알아볼 예정!)
2022년 11월 18일