4. Spider(크롤러) 만들기 > 4-3. Robots.txt(로봇 배제 표준)
Robots.txt(로봇 배제 표준)
웹페이지를 크롤링하기 전에 한 가지 확인해야 되는 것이 있는데, 바로 사이트의 robots.txt입니다.
robots.txt는 웹사이트의 최상위 디렉토리에 배치되어 있는 텍스트 파일입니다. 사이트의 주소에 /robots.txt를 붙여주면 확인할 수 있어요. robots.txt는 아래 지시어를 사용해 spider에게 정보를 전달합니다.
📖 대표적인 지시어
| 지시어 | 설명 |
|---|---|
| User-agent | 지시어 정보의 대상이 되는 웹크롤러 |
| Disallow | 크롤링을 거부할 경로 |
| Allow | 크롤링을 허가할 경로 |
| Sitemap | XML 사이트 맵의 URL |
| Crawl-delay | 웹크롤러가 지켜주길 희망하는 크롤링 시간 간격 (settings.py의 DOWNLOAD_DELAY 설정) |
사실 robots.txt는 강제성이 없습니다. 웹크롤러가 지시를 따를지 아닐지는 그것을 만드는 사람의 자유. 다만 상대의 웹사이트에 폐를 끼치지 않는 매너 있는 사람이 되고 싶다면 따르는 것을 권장합니다.
몇 가지 예시를 통해 robots.txt를 해석하는 방법을 익혀보겠습니다.
# 예 1)
User-agent: * # 모든 크롤러 대상
Disallow: / # /로 시작하는 모든 페이지의 크롤링을 허가하지 않음(즉, 사이트 전체)
# 예 2)
User-agent: * # 모든 크롤러 대상
Disallow: # 공백: 모든 페이지의 크롤링을 허가함
# 예 3)
User-agent: * # 모든 크롤러 대상
Allow: /page # /page 하위 경로는 허가
Disallow: / # 그 외는 크롤링을 허가하지 않음
# 예 4)
User-agent: * # 모든 크롤러 대상
Disallow: / # 사이트 전체 크롤링 금지
User-agent: Googlebot # Googlebot 대상
Allow: * # 사이트 전체 크롤링 허가
Disallow: /private # /private 하위 경로는 허가하지 않음
이제 11번가 사이트의 robots.txt를 확인해보겠습니다.

robots.txt에 의하면 11번가는 사이트 전체의 크롤링을 금지하고 있습니다 😨
11번가에 문의하니 "브랜드 및 크롤링을 포함하여 저작권 및 상표권 등 지적재산권이 침해되지 않는 범위에서는, 회사의 권리가 미치지 않으므로 이 부분은 별도 관여하지 않는다."라고 답변이 왔습니다. 저희는 단순 학습 목적이니 괜찮은 것 같아요.
11번가가 허용했는데 다른 사이트도 괜찮겠지?라고 생각하지 마시고, robots.txt에서 크롤링을 금지하고 있다면 반드시 문의해보시길 바랍니다.
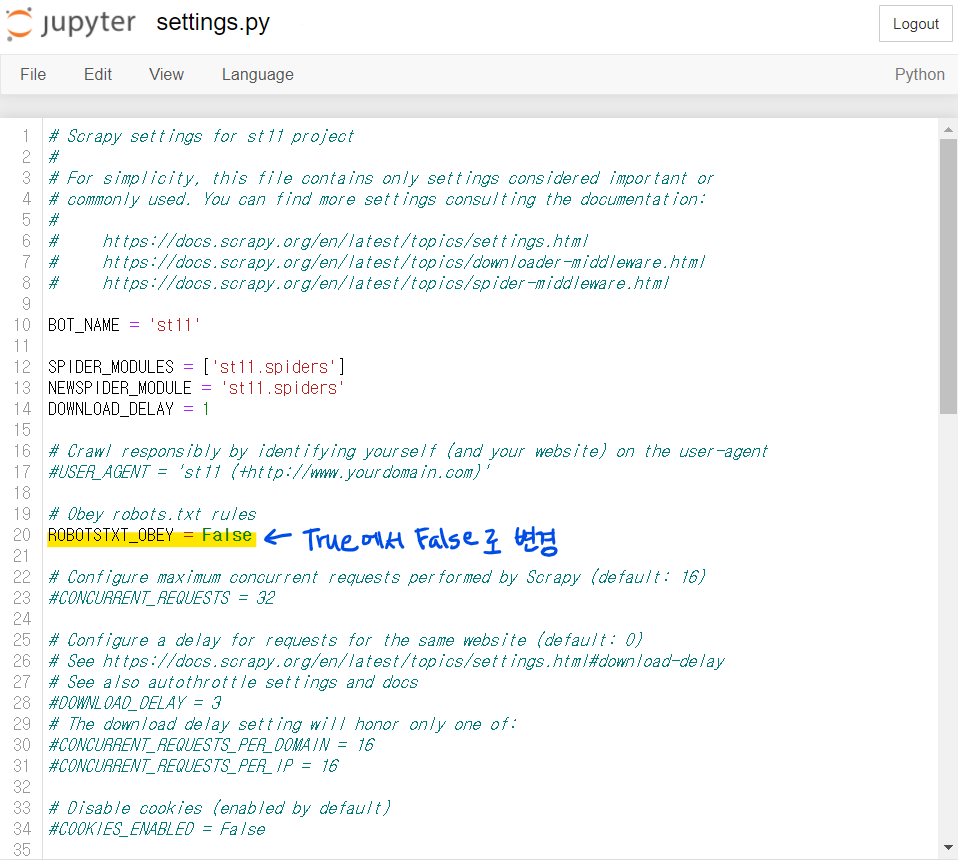
다시 돌아와서, 11번가와 같이 크롤링을 막아놓은 사이트는 settings.py의 설정을 변경해 주면 크롤링이 가능해집니다. [출처]
#settings.py
ROBOTSTXT_OBEY = False
spider를 실행해보면 이전(4-2. Spider 클래스)과 달리 웹페이지 정보가 크롤링된 것을 확인할 수 있습니다.
2022년 11월 18일